growR implements the grassland growth model ModVege. The
basis of the model is thoroughly described by (Jouven, Carrère, and Baumont 2006).
In short, ModVege takes values relating to daily weather conditions, the nutrition availability and water holding capabilities as well as the prevailing functional composition of plant population of the simulated site as inputs and uses them to simulate grass growth on a daily time step.
Functions and data provided by growR allow users to
- run grass growth simulations with ModVege,
- calibrate site and model parameters on the basis of reference data,
- carry out basic analysis into model outputs and performance.
The following section provides a step-by-step tutorial intended to
show how growR can be used. Deeper insights can be gained
by the vignette("parameter_descriptions").
Step 0: Goal of the tutorial
In this tutorial we are going to make use of the example input and reference datasets to go through the whole process of
- setting up all input files
- running ModVege simulations with the specified inputs
- have a look at the results
- change inputs and run a new simulation
Since quite a number of input files are required to even get started
with growR, the package ships with example files for each
of them. When following the tutorial, the reader will have an
opportunity to inspect all of them and can use those as templates in
order to create their own simulations with their own data.
When running simulations, data is loaded from and written to files.
In the following, we assume that we are working in an empty directory of
the filesystem and that this is the working directory for the running
R sessions or Rscript commands. To be on the
safe side, for this tutorial we will create a temporary directory
working_dir. All necessary or created files are assumed to
be located under this working directory.
working_dir = file.path(tempdir(), "growR_tutorial")
dir.create(working_dir)
setwd(working_dir)Step 1: Setting up all input files
To help users having a somewhat clean directory structure, the
function setup_directory() is provided. It also offers the
option to copy all example files from the package directory into
appropriate location in the newly created directory structure. Our first
step is therefore to execute the following from an R
session:
library(growR)
#> +--------------------------------------+
#> | Welcome to growR Version 1.3.0.9001! |
#> +--------------------------------------+
# Check that working directory is correct
print(working_dir)
#> [1] "/tmp/RtmplqKrsQ/growR_tutorial"
getwd()
#> [1] "/tmp/RtmplqKrsQ/growR_tutorial"
setup_directory(working_dir, force = TRUE)
#> [INFO]Initialized directory structure in `/tmp/RtmplqKrsQ/growR_tutorial`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux_weather.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux_parameters.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux_management1.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux_management2.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens_weather.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens_parameters.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens_management1.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens_management2.txt` to `/tmp/RtmplqKrsQ/growR_tutorial/input/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux1.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/data/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/posieux2.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/data/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens1.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/data/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/sorens2.csv` to `/tmp/RtmplqKrsQ/growR_tutorial/data/`.
#> [INFO]Copying `/home/runner/work/_temp/Library/growR/extdata/example_config.txt` to `/tmp/RtmplqKrsQ/growR_tutorial`.
#> [INFO]Copied example files to respective directories.We used force = TRUE here such that we can skip the
safety prompt which would otherwise ask for confirmation.
Afterwards, check the working directory. You should find a couple of subdirectories and some files:
-
outputThis is where generated output will be written to, by default -
inputInputs to the simulation, such as weather and management data are stored here. -
dataExperimentally measured, real world data comes here.
First, we’ll have a look at example_config.txt. We are
later going to adjust and make use of this file for running our
simulation in this tutorial. It contains information about the types of
simulation we want to run and what input files should be used for each
simulation. Have a look at its structure and compare it to the
explanations given in the documentation of
read_config().
As you can infer, in order to completely run a simulation, we require
at least a parameter and a weather data file (the management file is
optional). growR comes with example data for two real-world
experimental sites: Sorens and Posieux, both in Switzerland. You can
find the respective example parameter files at
input/sorens_parameters.csv and
input/posieux_parameters.csv. Likewise for the
input/..._weather.txt and
input/..._management1/2.txt files. Again, have a look at
these files and the respective descriptions in WeatherData
and ManagementData to familiarize yourself with the
required data structures and the meaning of the different columns.
2. Run ModVege with the example configuration
Everything is now set up for us and we are ready to proceed with a simulation. Run:
environments = read_config("example_config.txt")As you may have already seen from the documentation of
read_config(), this reads in the given configuration file,
skipping any lines starting with #. For each line, it then
looks for the given input files and creates a
ModvegeEnvironment object with the data from the
corresponding files. These ModvegeEnvironments are
essentially data structures that hold all the information needed in
order to run a ModVege simulation.
We are now ready to do so:
results = growR_run_loop(environments,
output_dir = file.path(working_dir, "output"))
#> [INFO]Starting run 1 out of 2.
#> [INFO] site name: `sorens1`.
#> [INFO] run name: `-`.
#> [INFO][Run 1/2]Simulating year 2013 (1/3)
#> [INFO][Run 1/2]Simulating year 2014 (2/3)
#> [INFO][Run 1/2]Simulating year 2015 (3/3)
#> [INFO]Starting run 2 out of 2.
#> [INFO] site name: `posieux1`.
#> [INFO] run name: `-`.
#> [INFO][Run 2/2]Simulating year 2013 (1/3)
#> [INFO][Run 2/2]Simulating year 2014 (2/3)
#> [INFO][Run 2/2]Simulating year 2015 (3/3)
#> [INFO]All runs completed.This will simulate grass growth for every year in every environment
present in environments. After some console output, we now
have the results of these runs in the list results. Check
the documentation of growR_run_loop() ro see how this list
is organized.
Furthermore, the default value for write_files in
growR_run_loop() is TRUE. This means that the
results have also been written to files in the output
directory.
3. Have a look at the results
Since we have the simulation results at our fingertips in our
interactive R sessions, the quickest way to inspect them is
through the results list. The output of
# Just print the first years of the first run (i.e. year 2013 at site Sorens)
results[[1]][[1]]
#> <ModvegeSite>
#> Public:
#> ABSDR: 0
#> ABSDV: 0
#> AET: 0.425137788528002 0.4583695833186 0.514875174072729 0.59 ...
#> AgeDR: 502.41 502.7 502.7 505.98 510.39 512.89 512.89 514.12 51 ...
#> AgeDRp: 3040.04026390736
#> AgeDV: 502.41 502.7 502.7 505.98 510.39 512.89 512.89 514.12 51 ...
#> AgeDVp: 386.161133811613
#> AgeGR: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> AgeGRp: 2295.17765333274
#> AgeGV: 102.41 102.7 102.7 105.98 110.39 112.89 112.89 114.12 11 ...
#> AgeGVp: 370.304808951
#> Autocut: NULL
#> BM: 747.72255 747.45043420575 747.45043420575 744.3753243852 ...
#> BM_after_cut: 1070
#> BMDR: 29.89155 29.87854717575 29.87854717575 29.7315447236453 ...
#> BMDRp: 0.47395457909275
#> BMDV: 297.831 297.57188703 297.57188703 294.643779661625 290.7 ...
#> BMDVp: 282.479780549091
#> BMG: 420 420 420 420 420 420 420 420 420 420 420 420 420 420 ...
#> BMGR: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> BMGRp: 140
#> BMGV: 420 420 420 420 420 420 420 420 420 420 420 420 420 420 ...
#> BMGVp: 491.438808210511
#> cBM: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> cBMp: 7841.72955659756
#> clone: function (deep = FALSE)
#> cut_DOYs: 106 134 162 190 218 246 274 302
#> cut_during_growth_preriod: TRUE
#> cut_height: 0.05
#> days_per_year: 365
#> dBM: -2.27745 -0.27211579425 0 -3.07510982047989 -4.094811373 ...
#> determine_cut: function (DOY)
#> determine_cut_from_input: function (DOY)
#> ENV: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> ENVfPAR: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...
#> ENVfT: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> ENVfW: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ...
#> get_management: function ()
#> get_weather: function ()
#> GRO: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> GROGR: 0
#> GROGV: 0
#> hvBM: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> initialize: function (parameters, site_name = "-", run_name = "-")
#> j_start_of_growing_season: 100
#> LAI: 0.811104 0.811104 0.811104 0.811104 0.811104 0.811104 0. ...
#> LAIGV: 0.811104 0.811104 0.811104 0.811104 0.811104 0.811104 0. ...
#> management: list
#> n_state_variables: 31
#> OMD: 0.677550945529553 0.677584798186734 0.677584798186734 0. ...
#> OMDDR: 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 ...
#> OMDDV: 0.45 0.45 0.45 0.45 0.45 0.45 0.45 0.45 0.45 0.45 0.45 0 ...
#> OMDG: 0.858665597014925 0.858576865671642 0.858576865671642 0. ...
#> OMDGR: 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0 ...
#> OMDGV: 0.858665597014925 0.858576865671642 0.858576865671642 0. ...
#> parameters: ModvegeParameters, R6
#> PGRO: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> plot: function (...)
#> plot_bm: function (smooth_interval = 28, ...)
#> plot_growth: function (...)
#> plot_limitations: function (...)
#> plot_var: function (var, ...)
#> plot_water: function (...)
#> REP: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
#> run: function (year, weather, management)
#> run_name: -
#> SENGR: 0
#> SENGV: 0
#> set_parameters: function (params)
#> set_SGS_method: function (method)
#> site_name: sorens1
#> ST: 2.41 2.7 2.7 5.98 10.39 12.89 12.89 14.12 14.12 14.93 16 ...
#> state_variable_names: AgeGV AgeGR AgeDV AgeDR BMGV BMGR BMDV BMDR OMDGV OMDGR ...
#> time_step: 1
#> version: package_version, numeric_version
#> weather: list
#> WR: 160 159.600913343104 159.873592083394 159.849885542053 1 ...
#> write_output: function (filename, force = FALSE)
#> WRp: 159.800708876818
#> year: 2013
#> Private:
#> apply_cuts: function ()
#> calculate_ageing: function ()
#> calculate_digestibility: function ()
#> calculate_growth: function ()
#> calculate_temperature_sum: function ()
#> carry_over_from_last_day: function ()
#> check_if_simulation_has_run: function ()
#> current_DOY: 365
#> get_start_of_growing_season: function (first_possible_DOY = 30, consider_snow = FALSE, critical_snow = 1)
#> initialize_state_variables: function ()
#> make_header: function ()
#> minBMGR: 56
#> minBMGV: 184
#> REP_ON: 0.653846153846154
#> SGS_method: MTD
#> SGS_options: MTD simple
#> update_biomass: function ()
#> vars_to_exclude: OMDDV OMDDR
#> ylabels: listmight be a little overwhelming and not very helpful, though. A
convenient way to quickly see what has happened is to plot the resulting
grass growth curves. The ModvegeSite() objects which are
actually what’s stored in results provide a simple means of
doing that through the plot() and the
ModvegeSite()s plot_XXX() methods.
For example, to get an overview over the time evolution of the biomass we could simply do:
results[[1]][[1]]$plot_bm()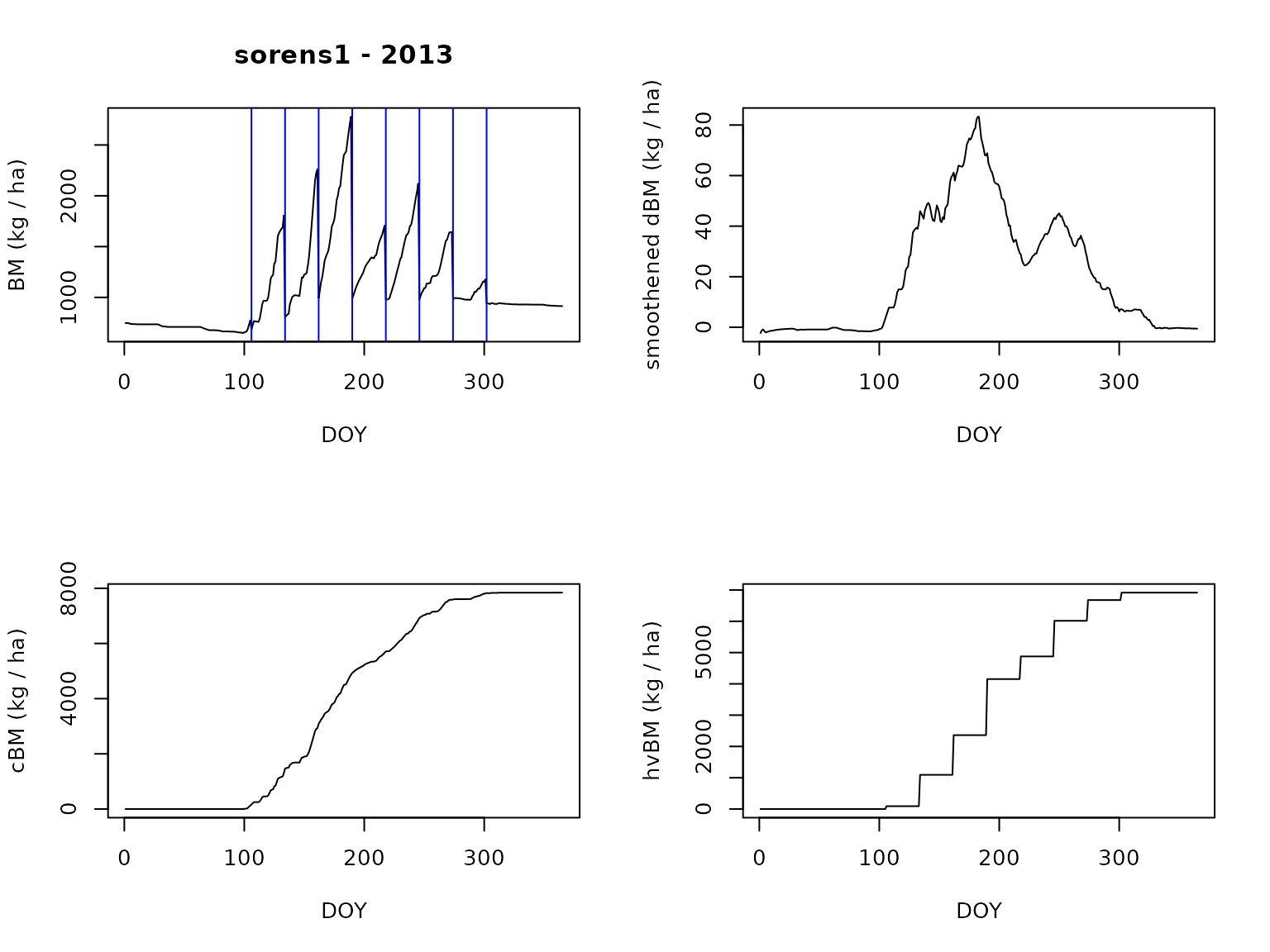
The blue vertical lines in the BM versus DOY plot
indicate the cutting events. They coincide with the steps visible in the
bottom right plot, showing harvested biomass versus DOY. Also
have a look at the related plot_XXX functions of
ModvegeSite() objects.
Excellent! You have run your first ModVege simulation with
growR!
4. Change inputs and run a different simulation
Now, for the sake of the example, let’s say that you want to check
what the simulation would look like if both sides had a significantly
lower nutritional index NI. First, check the current values
of NI in the differnet parameter files
(input/sorens_parameters.csv and
input/posieux_parameters.csv). They should be 0.7 for both
sites.
We want to investigate what the growth curves look like for different values of NI. For that purpose, we’ll focus only on the site Sorens and only on the year 2013 (just to keep the calculations required for the example quick).
One way to supply different parameters to the simulation, is by
providing different parameter files. Copy
sorens_parameters.csv twice and call the copies something
like sorens_parameters_lowNI.csv and
sorens_parameters_highNI.csv. In one of the files, change
the value of NI to 0.5 and in the other, change it to 1.0.
Then, copy the example_config.txt file, give it a name
of your choice (we’ll use NI_screening.txt here) and edit
it such that there are only three uncommented lines. All of them should
use site name sorens1 and only the year 2013. One of them
should use the original sorens_parameters.csv file while
the others should use the newly written parameter files with higher and
lower NI values respectively. Since we now specify several
runs with the same site name, we need to distinguish them by
giving at least two of them a distinct run name as well.
When done, your new config file might look something like this:
# site name # run name # year(s) # param file # weather data # cut dates
sorens1 - 2013 sorens_parameters.csv sorens_weather.txt sorens_management1.txt
sorens1 lowNI 2013 sorens_parameters_lowNI.csv sorens_weather.txt sorens_management1.txt
sorens1 highNI 2013 sorens_parameters_highNI.csv sorens_weather.txt sorens_management1.txtBe sure that the spelling of your file names is correct and
consistent and that all the files reside in the correct locations
(i.e. the input directory under our working directory).
If all seems fine, go for it (use the name of the config file you chose):
new_envs = read_config("NI_screening.txt")And we’re ready to run and inspect our next run of simulations:
new_results = growR_run_loop(new_envs)
#> [INFO]Starting run 1 out of 3.
#> [INFO] site name: `sorens1`.
#> [INFO] run name: `-`.
#> [INFO][Run 1/3]Simulating year 2013 (1/1)
#> [INFO]Starting run 2 out of 3.
#> [INFO] site name: `sorens1`.
#> [INFO] run name: `-`.
#> [INFO][Run 2/3]Simulating year 2013 (1/1)
#> [INFO]Starting run 3 out of 3.
#> [INFO] site name: `sorens1`.
#> [INFO] run name: `-`.
#> [INFO][Run 3/3]Simulating year 2013 (1/1)
#> [INFO]All runs completed.
# Plot all results
for (run in new_results) {
print(run[[1]]$parameters$NI)
run[[1]]$plot()
}
#> [1] 0.7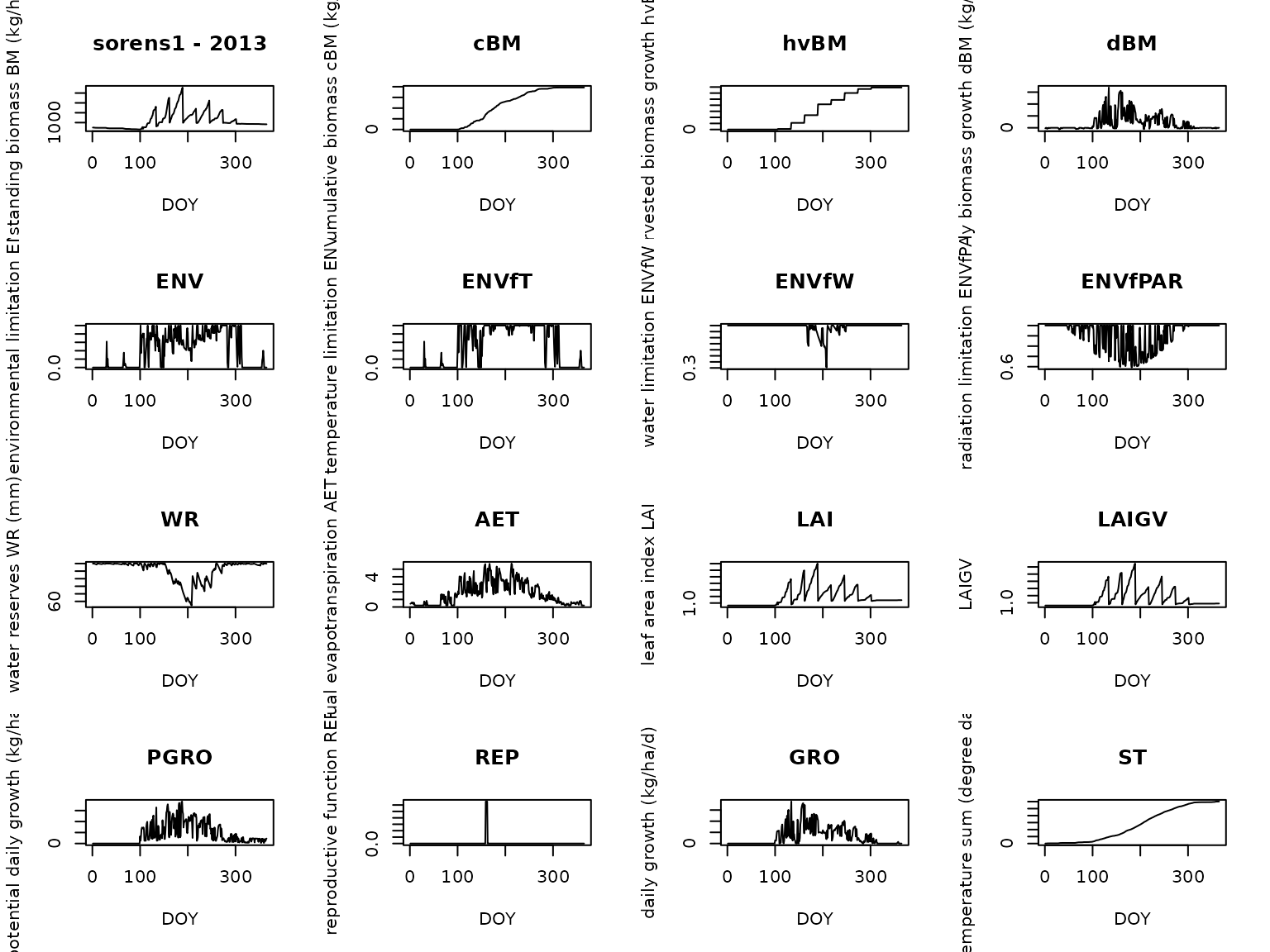
#> [1] 0.5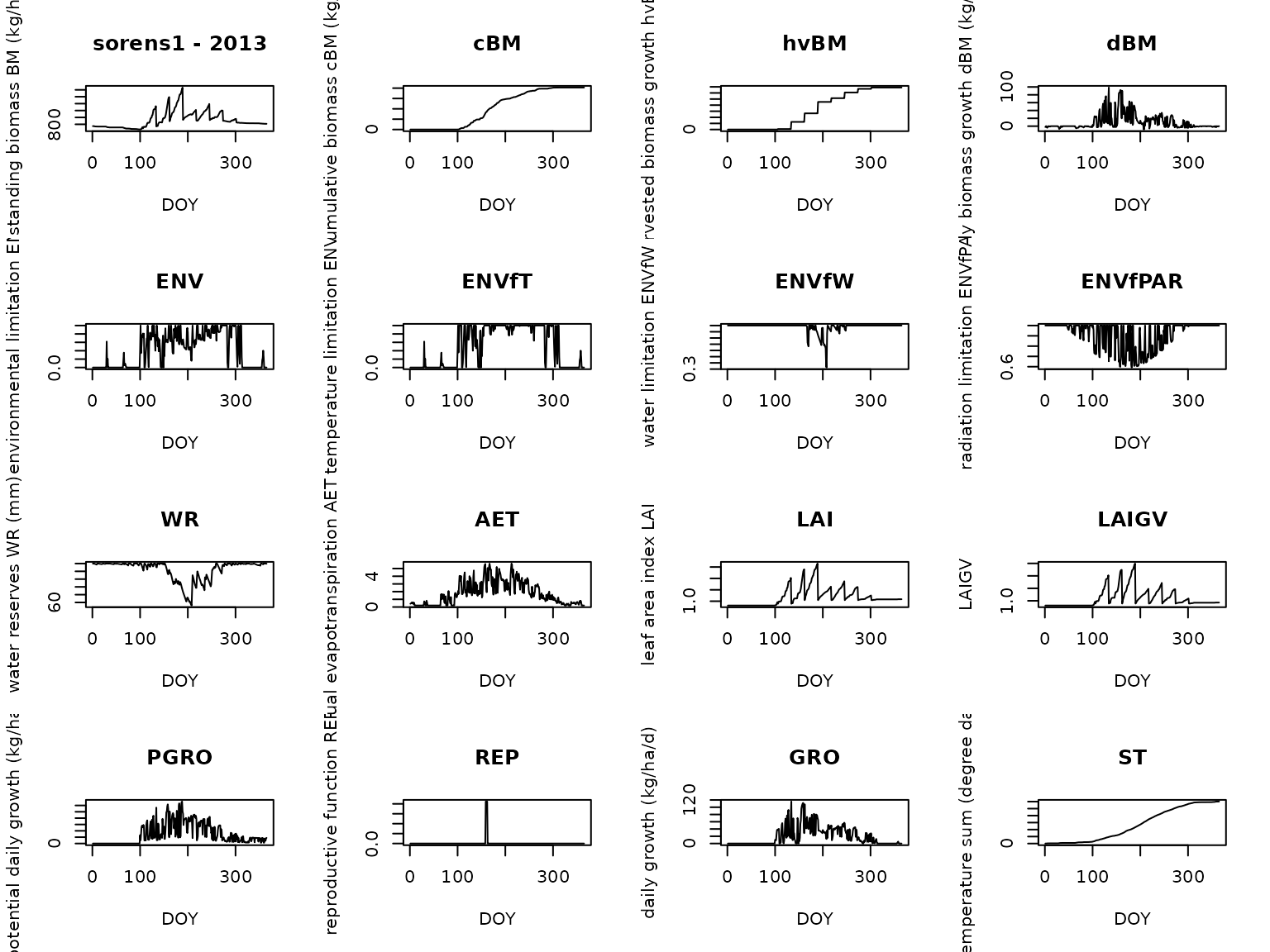
#> [1] 1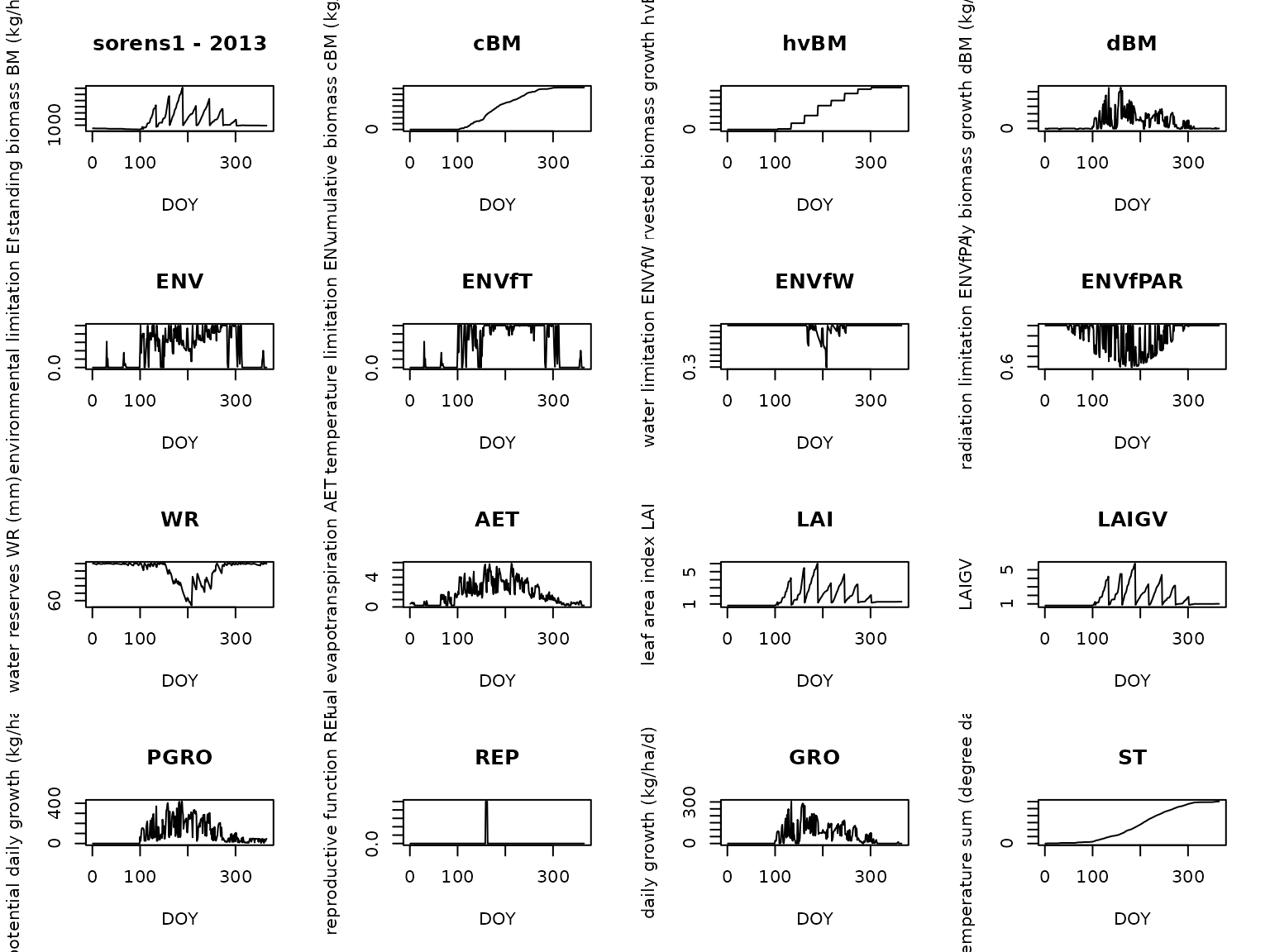
We can see how NI affects the total biomass production:
larger NI leads to proportionally larger cBM
and hvBM by the end of the season.